



A bold statement that is more of a personal opinion rather than a proven, data-supported scientific fact of life. So, I wouldn’t advise you to spend the rest of your afternoon trying to prove me wrong cause I am also OK with that. It is just my opinion based on what I’ve experienced at a personal and professional level.
But again, I am not writing today to support that statement with statistical data, case studies and research outcomes to convince you. I am rather more interested in sharing my experience and that of T60 on how we approached and designed a Monitoring and Recovery System that would diminish the impact, severity and downtime of a major industrial machine by combining both automated and manual recovery solutions.
… a Monitoring and Recovery System that would diminish the impact, severity and downtime of a major industrial machine by combining both automated and manual recovery solutions.
In this article, I want to share with you an overview of our technology agnostic approach, at a high level of abstraction, for how we conceptualized the main elements that should be implemented in any Monitoring and Recovery System, regardless of what industry you are in, machine you are operating or technology you are leveraging.
But first, let’s start with the basics …
What is machine failure?
Machine Failure is the event in which a piece of machinery underperforms, stops functioning or deviates from its normal operating condition. The failure could have several severity levels, could be partial or complete and could have a minimal or catastrophic impact. For our purposes, any malfunction in the machinery is considered a machine failure.
Just to be clear, I am referring here to industrial machinery where any disruption to its normal operating mode could halt production and cause loss of value and revenues and a damaging impact to the reputation of a business.
As a business owner, plant/factory manager or a stakeholder in a machinery-operating business, it is in your best interest to ensure minimal disruption and downtime to your machines to avoid costly losses by having monitoring and recovery measures implemented in place. This can be achieved through a Monitoring and Recovery System.
So, let’s now get to the core of why you are here …
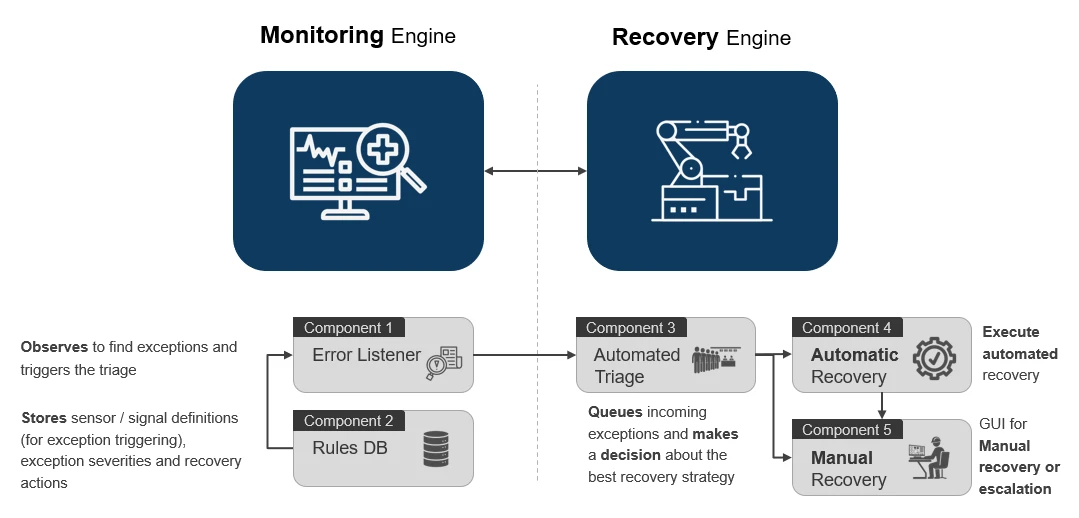
The 5 main components of a Monitoring and Recovery System
The monitoring part (let’s call it the Monitoring Engine for simplicity) is comprised of:
- Error Listener: observes events to recognize potential failures and accordingly trigger a triage process
- Rules DB: stores events definitions, thresholds, normal and error levels and possible recovery action(s) to be taken once the event is recognized as an exception
While the recovery part (call it the Recovery Engine) consists of:
- The Triage: (triggered by the Error Listener) queues and analyses errors, prioritizes execution and triggers the most appropriate recovery scenario (automatic or manual)
- Automated Recovery: automatically executes pre-defined actions, based on the nature, severity and type of error, in an attempt to bring a machine back to its normal operating/productive state without manual/human intervention
- Manual Recovery: provides detailed status report, manual recovery instructions/steps, and calls to action to the machine operator(s) in order to quickly make informed decisions and fix the error(s) if the automated recovery measures fail or was not applicable yet for that specific type of error
Let’s talk about the functionality and role of component in brief …
Component 1: Error listener
The error listener does exactly that;  listens, listens and listens … and then again listens to non-stop events taking place all the time across the different subsystems of your machine and waiting to detect an anomaly (i.e. an exception) to the standard flow of operations. Once an exception is detected, the error listener immediately informs the recovery manager; in that case the triage component is triggered in order to start taking the necessary actions.
listens, listens and listens … and then again listens to non-stop events taking place all the time across the different subsystems of your machine and waiting to detect an anomaly (i.e. an exception) to the standard flow of operations. Once an exception is detected, the error listener immediately informs the recovery manager; in that case the triage component is triggered in order to start taking the necessary actions.
The error listener does exactly that; listens, listens and listens … and then again listens to non-stop events taking place all the time across the different subsystems of your machine.
But what type of events should the dog, I mean the error lister, observe, monitor and listen to? There could be millions of transactions, events and operations being executed at any point in time! How would the listener know if an event is classified as an error? Is there a threshold that should not be exceeded by a sensor for example? Is a warning different than an error? What makes a warning a warning and an error an error?
The answers to all those questions reside within component 2 … the Rules DB.
Component 2: Rules DB
This is the single source of truth of a Monitoring and Recovery System.
The Rules DB stores all the details of all the events that we want monitored, whose values should be kept within a certain range and whose thresholds, if exceeded, would cause a disruption to the normal operation of the machine. Those events are the one that the Error Listener should subscribe to and keep tabs on at all times. The Rules DB is a configurable component to allow for a continuous, up to date editing of events and the actions required to recover a disruption.
An event is usually stored with the following main attributes:
- Name and unique ID
- Values for normal, warning and error modes
- Recovery action (ex: stop machine, restart DB, send email to operator, shut down valve, etc.)
Something doesn’t feel right and errors start firing? This is when The Triage kicks in …
Component 3: The triage
Remember the last time you had to rush to the emergency department crying out in pain expecting to be admitted immediately only, to your utter shock and surprise, to find out that you would have to wait for a few hours before you got examined. You were sure though you detailed your situation and clearly communicated the pain level! Well … blame the triage.
By the same analogy, the Triage component sits at the heart of a Monitoring and Recovery System and is responsible for queuing the exceptions and deciding which one(s) should be handled first based on a combination of factors like queue position, severity, impact, resolution time, etc.
… the Triage is the heart of a Monitoring and Recovery System …
The Triage component plays three critical roles:
- Queuing of errors/exceptions to ensure that the information gathering and default execution is sequential.
- Information gathering about the type, time, severity, recovery steps of the error and the current state of the machine before any actions could be taken.
- Triggering of recovery action(s) that is defined in the Rules DB; this could be an automatic recovery or a manual recovery where the intervention of a member of the operations team is required.
Component 4: Automated recovery
This is where the real action takes place.
Once a failure is confirmed, pre-defined recovery actions are executed based on what is defined in the Rules DB. The objective is to recover the machine as quickly as possible to a state of normal operation and productivity. The Automated Recovery also gets to decide when to execute the recovery activity and whether the machine needs to be suspended, or current operation aborted, before the error could be fixed.
Examples of recovery actions could be: shut down temperature valve, lock waterflow gates, rollback a production DB if a DB migration fails, etc.
But what if something still goes wrong and the machine can not automatically recover from a failure? There should always be a fallback plan once your automated solution/approach falls short, which will often happen due to countless reasons. In our case, the fallback approach is the manual recovery.
“There should always be a fallback plan once your automated approach falls short, which will often happen due to countless reasons. In that case, enter manual recovery.”
Component 5: Manual recovery
Have you ever woken up in the middle of the night on a call from your operations team screaming that the place is on fire and a manual rollback of the production DB is immediately required because your automation tools had failed to solve the problem!
Usually overlooked, the manual recovery component is as critical as the automated one. It is our fallback plan when things go south (and I intentionally used ‘when’ not ‘if’ because failure will eventually happen) or when an automatic recovery action is not yet defined.
 This is the case when a machine can not recover on its own and needs manual intervention (someone to flip it back over) to go back to its normal operating mode and become productive again.
This is the case when a machine can not recover on its own and needs manual intervention (someone to flip it back over) to go back to its normal operating mode and become productive again.
The manual recovery is responsible for providing detailed status report(s), manual recovery instructions/steps and calls to action to the machine operator(s) to assist them quickly make informed decisions and fix the error(s); this could be in the form of an email notification or a GUI where the operations team can search for similar errors, read detailed instructions about how to fix an error or sometimes even escalate the issue to a 3rd level support team.
The takeaways
In conclusion, it is important to understand that any machine will eventually fail! Again, my personal opinion! Failure is inevitable and has to be treated as such. It is our role to make sure that we have the proper measures in place that would help us quickly recover from costly downtimes.
Happy Recovery! We all need it during this stressful time!
